










Open LLM Leaderboard是什么
Open LLM Leaderboard 是最大的大模型和数据集社区 HuggingFace 推出的开源大模型排行榜单,基于 Eleuther AI Language Model Evaluation Harness(Eleuther AI语言模型评估框架)封装。Open LLM Leaderboard通过多种基准测试(如 IFEval、BBH、MATH 等),从指令遵循、复杂推理、数学解题、专业知识问答等多个维度对模型进行评估。排行榜涵盖预训练模型、聊天模型等多种类型,提供详细的数值结果和模型输入输出细节。Open LLM Leaderboard 能帮助用户筛选出当前最先进的模型,推动开源社区的进步。
Open LLM Leaderboard 的主要功能
- 多维度基准测试:包括多种基准测试(如 IFEval、BBH、MATH、GPQA 等),涵盖指令遵循、复杂推理、数学解题、专业知识问答等多个领域,全面评估模型能力。
- 多种模型类型支持:支持预训练模型、持续预训练模型、领域特定微调模型、聊天模型等,覆盖不同应用场景。
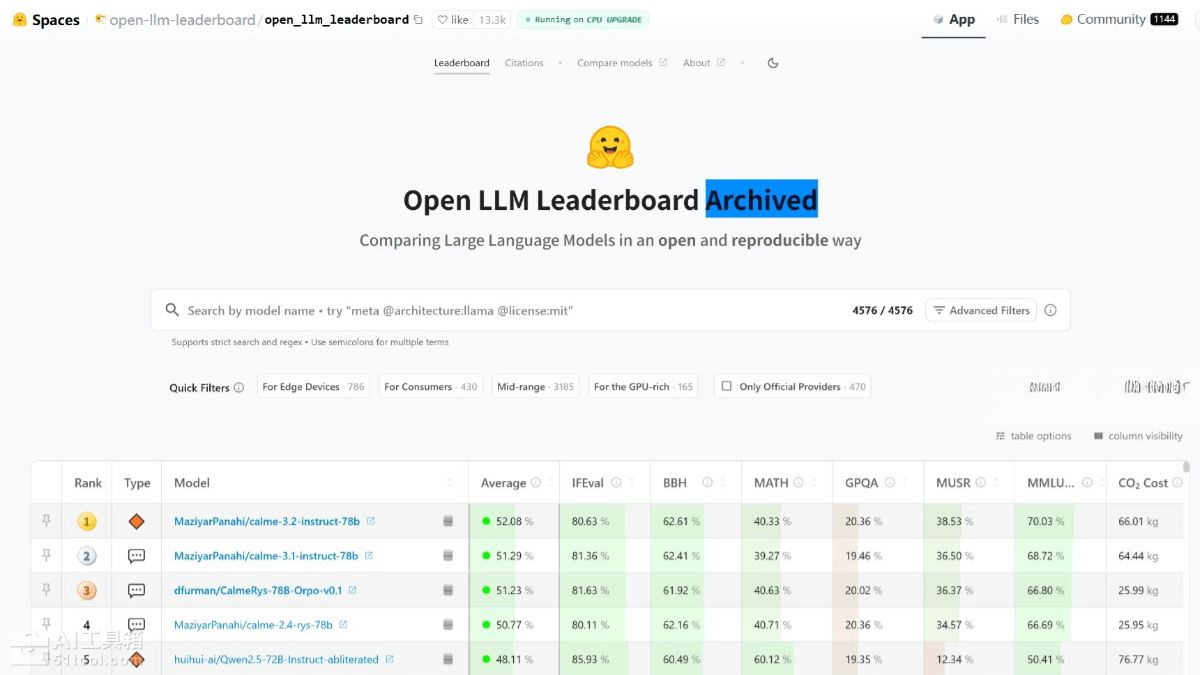
- 详细结果展示:提供详细的数值结果和模型输入输出细节,帮助用户深入了解模型表现。
- 社区互动:社区成员对模型进行标记和讨论,确保排行榜的公正性和透明度。
- 可复现性支持:提供代码和工具,帮助用户复现排行榜上的结果,增强研究的可信度。
Open LLM Leaderboard 的评估基准
- IFEval:评估模型遵循明确指令的能力,如格式要求,使用严格准确率指标。
- BBH(Big Bench Hard):用23个高难度子任务,涵盖多步算术、算法推理和语言理解,测试模型的综合能力。
- MATH:测试模型解决高中竞赛级别数学问题的能力,要求严格遵循特定输出格式。
- GPQA(Graduate-Level Google-Proof Q&A Benchmark):由专家设计的高难度知识问答任务,涵盖多领域专业知识。
- MuSR(Multistep Soft Reasoning):用复杂多步推理问题,如谋杀案谜题,评估模型的长距离上下文解析和推理能力。
- MMLU-PRO(Massive Multitask Language Understanding – Professional):改进版的多任务语言理解评估,增加选择数量,提高问题难度,减少噪声。
如何使用Open LLM Leaderboard
- 访问排行榜页面:访问 Open LLM Leaderboard 页面,查看当前的模型排名和性能数据。
- 查看模型详情:点击感兴趣的模型名称,查看详细信息。
- 筛选和比较模型:用排行榜页面提供的筛选功能,根据模型类型、性能指标等条件筛选模型。对比不同模型在各基准测试中的表现,选择最适合需求的模型。
- 复现评估结果:如果需要复现某个模型的评估结果,用 Hugging Face 提供的代码工具:
git clone git@github.com:huggingface/lm-evaluation-harness.git
cd lm-evaluation-harness
git checkout main
pip install -e .
lm-eval --model_args="pretrained=<your_model>,revision=<your_model_revision>,dtype=<model_dtype>" --tasks=leaderboard --batch_size=auto --output_path=<output_path>