HELM是什么
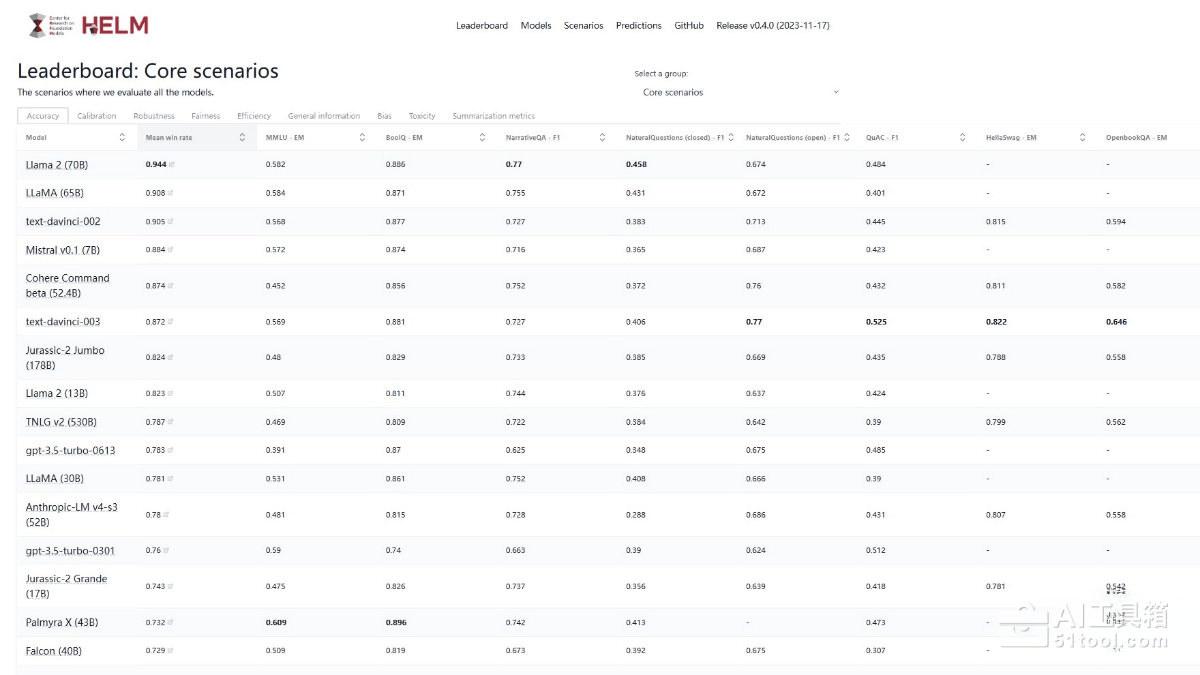
HELM全称Holistic Evaluation of Language Models(语言模型整体评估)是斯坦福大学推出的大模型评测体系,评测方法主要包括场景、适配、指标三大模块,每次评测的运行都需要指定一个场景,一个适配模型的提示,以及一个或多个指标。它评测主要覆盖的是英语,通过准确率、不确定性/校准、鲁棒性、公平性、偏差、毒性、推断效率综合评测模型表现,适用问答、信息检索、文本分类等任务,为语言模型提供更全面、系统的评估方法,帮助研究人员和开发者更好地理解和优化模型性能。

HELM的主要功能
- 全面的评估能力:HELM支持多种语言模型任务(如问答、文本分类、信息检索、文本生成、摘要等),提供多种评估指标(包括准确率、鲁棒性、公平性、偏差、毒性、推断效率等),能够从多个维度全面评估语言模型的性能。
- 可复现性与透明性:HELM基于标准化的评估流程和配置文件,确保不同用户在相同条件下能够获得一致的评估结果,用户能查看和修改评估代码,保证评估过程的透明性和可定制性。
- 多模态支持:HELM不仅支持纯文本任务,还支持多模态任务(例如图像描述生成、视觉问答等),评估多模态模型的综合性能。
- 自定义扩展:用户根据自己的需求,自定义评估任务、适配策略和指标,HELM提供灵活的扩展机制,满足特定的研究或应用需求。