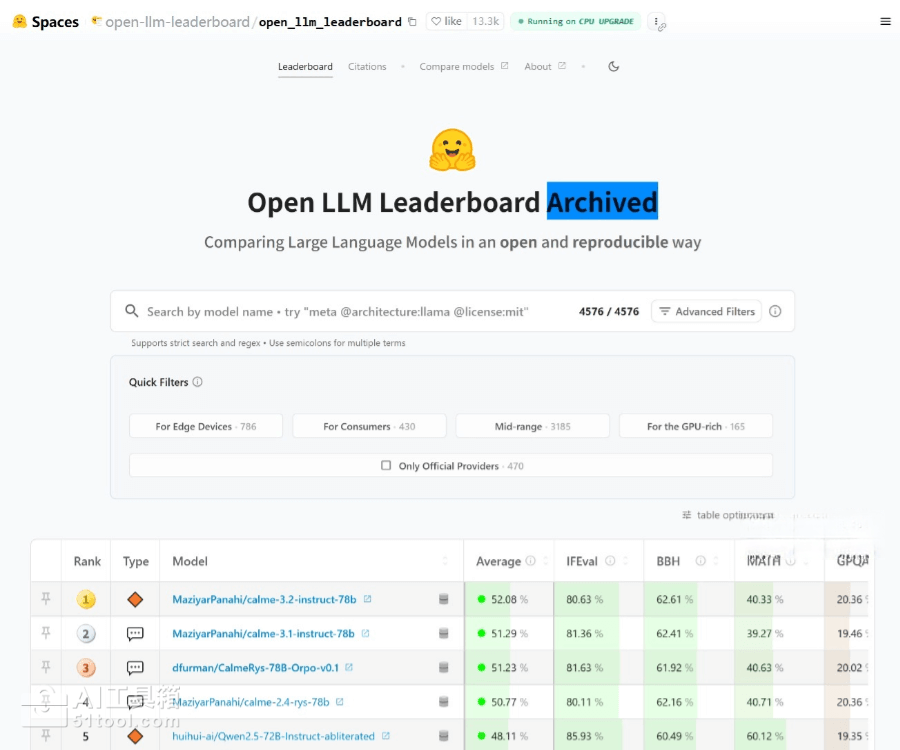
Open LLM Leaderboard是什么
Open LLM Leaderboard是Hugging Face于2020年推出的开源大语言模型评测平台,基于EleutherAI LM Evaluation Harness框架,通过ARC、HellaSwag、MMLU、TruthfulQA等标准化基准测试,对开源大语言模型进行多维度性能评估和排名,帮助开发者、研究人员和企业决策者快速识别最先进的模型,推动AI技术的透明化发展和公平竞争。
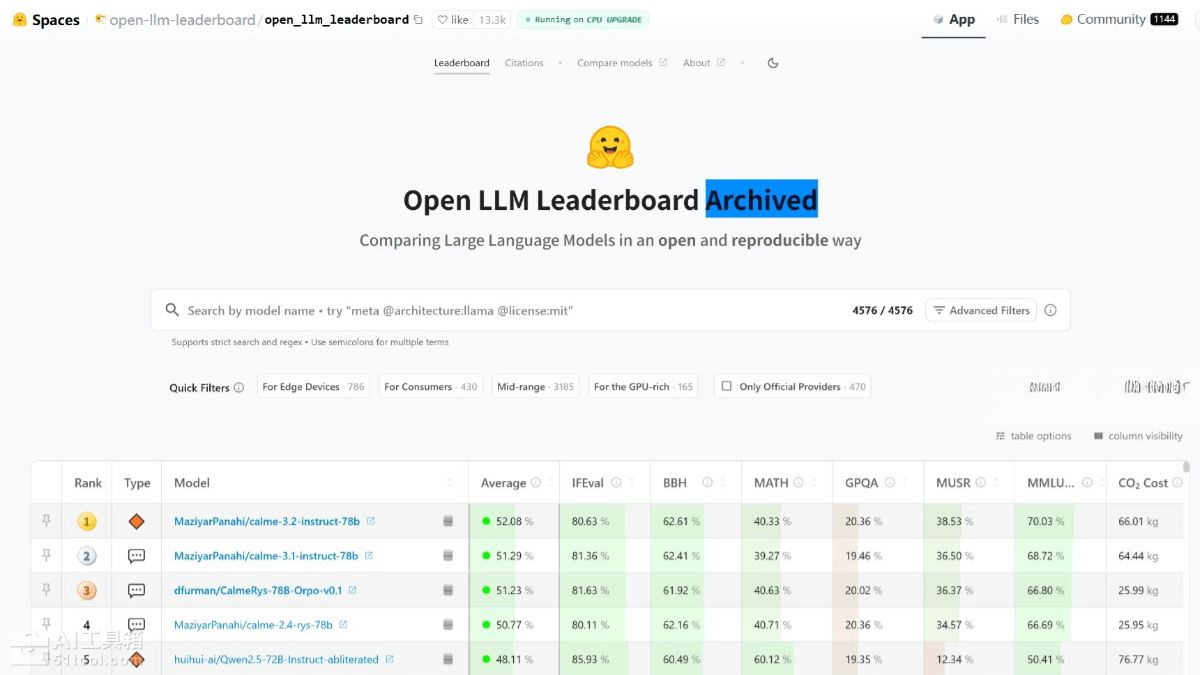
Open LLM Leaderboard的主要功能
多维度模型评估:涵盖AI2推理挑战、常识推理、多任务语言理解、事实真实性等六大核心任务,通过标准化评分体系(0-100分)全面衡量模型在推理、知识、数学、语言理解等方面的综合能力。
自动化评测流程:利用Hugging Face GPU集群自动运行评估任务,支持零样本和少样本测试模式,确保评测结果的可重复性和可比性,任何人都可以提交模型进行免费评估。
模型分类筛选:按模型类型(预训练、微调、指令精调)、精度(float16、8bit、4bit等)、参数规模(1.5B-70B+)进行精细划分,用户可根据应用需求和部署条件针对性查看特定范围内的模型排名。
标准化评分体系:采用归一化分数计算,从随机基线(0分)到最高性能(100分)进行标准化,使较难的基准在最终评分中占比更大,确保评分的公平性和平衡性。
Open LLM Leaderboard的使用方法
- 访问官方网站:打开Hugging Face的Open LLM Leaderboard页面,查看当前模型排名和详细得分。
- 提交模型评估:在Hub上有权重的Transformers模型均可提交,系统会在GPU集群空闲时自动运行评估任务,结果保存在Hub数据集中并显示在排行榜上。
- 本地评估:使用官方的lighteval框架在本地运行与Open LLM Leaderboard完全相同的评估流程,在模型公开发布前了解性能差距。
Open LLM Leaderboard的产品价格
Open LLM Leaderboard是完全免费的评测平台,用户无需支付任何费用即可提交模型进行评估、查看排名结果,Hugging Face提供GPU计算资源支持自动化评测流程。
Open LLM Leaderboard的适用人群
AI研究人员:验证新模型或算法的性能,与现有模型进行公平比较,增强学术成果的可信度和影响力。
模型开发者:在模型公开发布前进行性能对标,指导优化方向,加速高质量模型的迭代与发布。
企业决策者:为特定业务场景选择合适AI模型提供客观、透明的决策依据,优化技术选型流程,降低采用开源模型的风险与成本。
总而言之,Open LLM Leaderboard是一款用于评估开源大语言模型综合性能的权威评测平台,通过标准化基准测试和自动化评估流程,为AI社区提供公平、透明的模型排名,帮助开发者、研究人员和企业快速识别最先进的模型,推动AI技术的持续发展和应用普及。