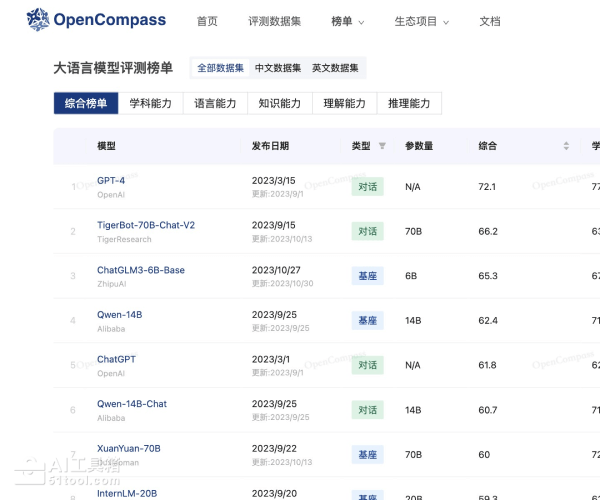
OpenCompass是什么
OpenCompass是上海人工智能实验室于2023年12月开源的大模型评测平台,通过多维度指标体系评估语言及多模态模型的综合能力。该平台涵盖学科、语言、知识、理解与推理五大核心维度,整合超过70个数据集和40万评测问题,支持分布式高效评测、多样化评测范式及中英双语基准测试,兼容HuggingFace开源模型与主流API模型接入,为研究人员和开发者提供全面、客观、可复现的大模型性能评估解决方案。
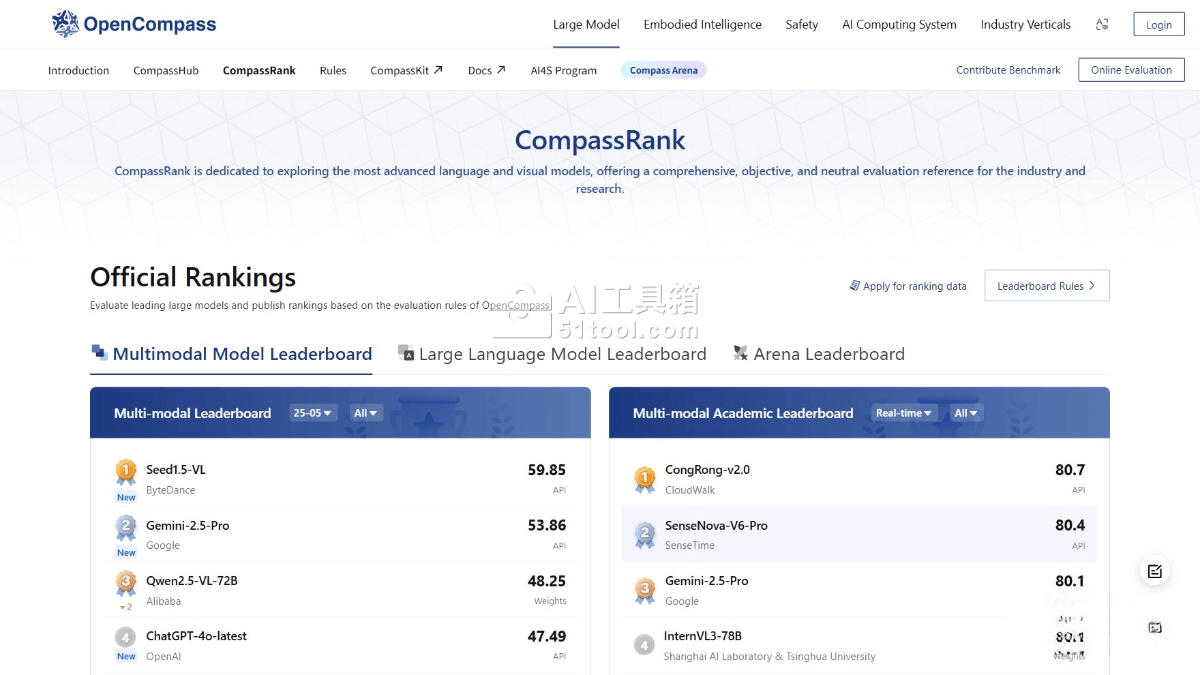
OpenCompass的主要功能
多维度能力评估:从语言、知识、理解、推理、安全等多个能力维度进行评测,细分为10项基础能力和70+项子能力,全面考察模型在语义理解、逻辑推理、代码生成、数学计算、知识百科、角色扮演、安全性等方面的综合表现。
丰富的模型支持:已支持20+个HuggingFace及API模型,包括Llama3、Mistral、InternLM2、GPT-4、LLaMa2、Qwen、GLM、Claude等主流大语言模型,无论是开源模型还是商业API模型都可以在平台上进行评估。
分布式高效评测:提供分布式评测方案,支持本机或集群上的计算任务并行分发,一行命令实现任务分割和分布式评测,数小时即可完成千亿模型全量评测,大幅提升评测效率。
多样化评测范式:支持零样本、小样本及思维链评测,结合标准型或对话型提示词模板,内置多种Prompt模板,最大程度激发各种模型最大性能,确保评测结果的准确性和可比性。
灵活化拓展:支持用户自定义的新模型或数据集进行测评,各模块可高效复用和拓展,可以自定义更高级的任务分割策略,甚至接入新的集群管理系统,满足不同用户的个性化需求。
OpenCompass的使用方法
- 环境配置:创建conda虚拟环境,安装Python 3.10和PyTorch等依赖包,从GitHub克隆OpenCompass源码并安装项目依赖。
- 数据准备:下载官方评测数据集到opencompass目录下解压为data目录,数据集包含核心数据集和完整数据集两种版本,用户可根据需求选择下载。
- 模型配置:通过命令行或配置文件方式配置待评估的模型和数据集,支持HuggingFace模型、API模型等多种格式,可指定评估策略、计算后端等参数。
- 运行评估:执行评估脚本,平台会自动进行并行评估,支持使用LMDeploy或vLLM等推理框架加速评估过程,大幅缩短评测时间。
- 查看结果:评估完成后,在终端或文件中查看详细的评估报告,包括各项指标的数值、对比图表等信息,了解模型在各维度的表现。
OpenCompass的产品价格
OpenCompass是完全免费的开源评测平台,用户无需支付任何费用即可使用所有评测功能、查看排行榜和下载评测报告,所有资源对研究社区开放。
OpenCompass的适用人群
AI研究人员:用于评估和比较不同大语言模型的性能,推动人工智能技术的发展,为学术研究提供客观、可复现的评测基准。
模型开发者:在开发自动生成工具、智能助手等项目时,利用平台评测结果优化模型性能,诊断模型的优势与不足,指导模型的进一步优化。
企业决策者:在产品开发中应用OpenCompass评估模型性能,为特定业务场景选择合适AI模型提供客观、透明的决策依据,优化技术选型流程。
教育工作者和学生:在教学中使用OpenCompass进行AI模型的教学和研究,帮助学生理解复杂的人工智能概念,培养AI领域的专业人才。
总而言之,OpenCompass是一款用于全面评估大模型认知能力的科学评测平台,通过"能力-任务-指标"三维框架、70+个数据集和40万评测问题的多维度评测体系,为研究人员、开发者和企业提供公正、透明、专业的模型性能评估工具,推动大模型技术的持续发展和应用普及。