LLMEval-3是什么
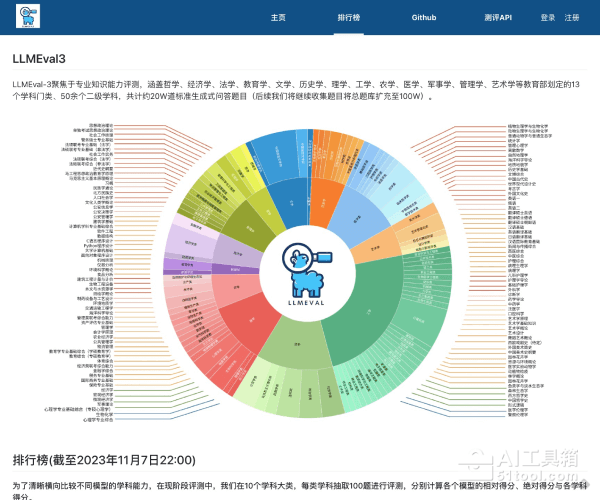
LLMEval-3(Large Language Model Evaluation-3)是复旦大学自然语言处理实验室于2023年推出的大模型评测基准,建立在LLMEval-1和LLMEval-2之上,是目前最全面的中文生成式知识问答评测平台。该基准采用"题库考试"模式,涵盖教育部划定的13个学科门类、50余个二级学科,共计约20万道标准生成式问答题目,旨在评估大模型在中文知识问答任务上的表现,并提供一个公平的比较平台。
LLMEval-3的主要功能
多学科知识评测:涵盖哲学、经济学、法学、教育学、文学、历史学、理学、工学、农学、医学、军事学、管理学、艺术学等13个学科门类,题目来源主要包括大学本科课后作业、期中期末考试、研究生入学考试等非互联网公开渠道,确保评测数据的原创性和防污染性。
生成式问答形式:与选择题模式不同,LLMEval-3将所有问题统一处理为生成式知识问答形式,包含简答、计算、判断、辨析、写作等多种题型,能够更好地反映用户实际需求以及模型语言能力。
防作弊机制:采用"题库考试"模式,每次评测从总题库中随机抽样1000题,针对同一机构的模型确保每次评测题目不重复。评测过程采用在线方式,题目的发送串行进行,避免恶意爬取行为,有效防止"刷榜"、"刷分"现象。
自动化评测流程:采用GPT-4自动评测方法打分,每道题得分范围为0-3分,评分聚焦于回答的核心正确性和解释正确性。使用相对分数和绝对分数两个指标,相对分数定义为模型绝对分数相比于GPT-3.5-turbo及GPT-4在相同题目上取得的绝对分数的分位,确保评测结果的客观性和可比性。
LLMEval-3的使用方法
- 访问官网:打开LLMEval-3官方网站(http://llmeval.com/),注册并登录账号。
- 准备模型:确保待评测的大模型可通过API或其他方式与评测系统交互,准备好模型文件和配置信息。
- 提交评测:通过平台提交模型信息,系统将从题库中随机抽取1000题进行评测,评测过程全自动运行。
- 查看结果:评测完成后,在平台上查看详细的评测报告,包括各项指标的数值、对比图表等信息,分析模型在各维度的表现。
LLMEval-3的产品价格
LLMEval-3是完全免费的开源评测基准,用户无需支付任何费用即可使用所有评测功能、查看排行榜和下载评测报告,所有资源对研究社区开放。
LLMEval-3的适用人群
AI研究人员:用于评估和比较不同大语言模型的性能,推动人工智能技术的发展,为学术研究提供客观、可复现的评测基准。
模型开发者:在开发自动生成工具、智能助手等项目时,利用平台评测结果优化模型性能,诊断模型的优势与不足,指导模型的进一步优化。
企业决策者:在产品开发中应用LLMEval-3评估模型性能,为特定业务场景选择合适AI模型提供客观、透明的决策依据,优化技术选型流程。
教育工作者和学生:用于教学评估,分析学生对中文的理解能力,帮助学生和研究人员掌握AI模型评测的方法和技巧。
总而言之,LLMEval-3是一款用于全面评估中文大模型知识储备和推理能力的权威评测基准,通过13个学科门类、50余个二级学科和约20万道生成式问答题目,为研究人员、开发者和企业提供科学、客观、中立的模型性能评估工具,推动中文大模型技术的持续发展和应用普及。