
### HELM是什么
HELM(Holistic Evaluation of Language Models,语言模型全面评估)是斯坦福大学于2022年推出的大模型评测框架,通过42个应用场景和7个核心指标的矩阵交叉评估,全面衡量语言模型在准确率、鲁棒性、效率、公平性、偏见、毒性和校准度等多维度的综合表现,为研究人员和开发者提供标准化、透明化、可复现的模型性能评估工具,帮助识别不同模型在能力、成本与社会风险之间的权衡取舍。

### HELM的主要功能
**多维度能力评估**:从语言理解与生成、知识理解与应用、专业能力、环境适应与安全性四大象限,细分为10项基础能力和70+项子能力,全面考察模型在语义理解、逻辑推理、代码生成、数学计算、知识百科、角色扮演、安全性等方面的综合表现。
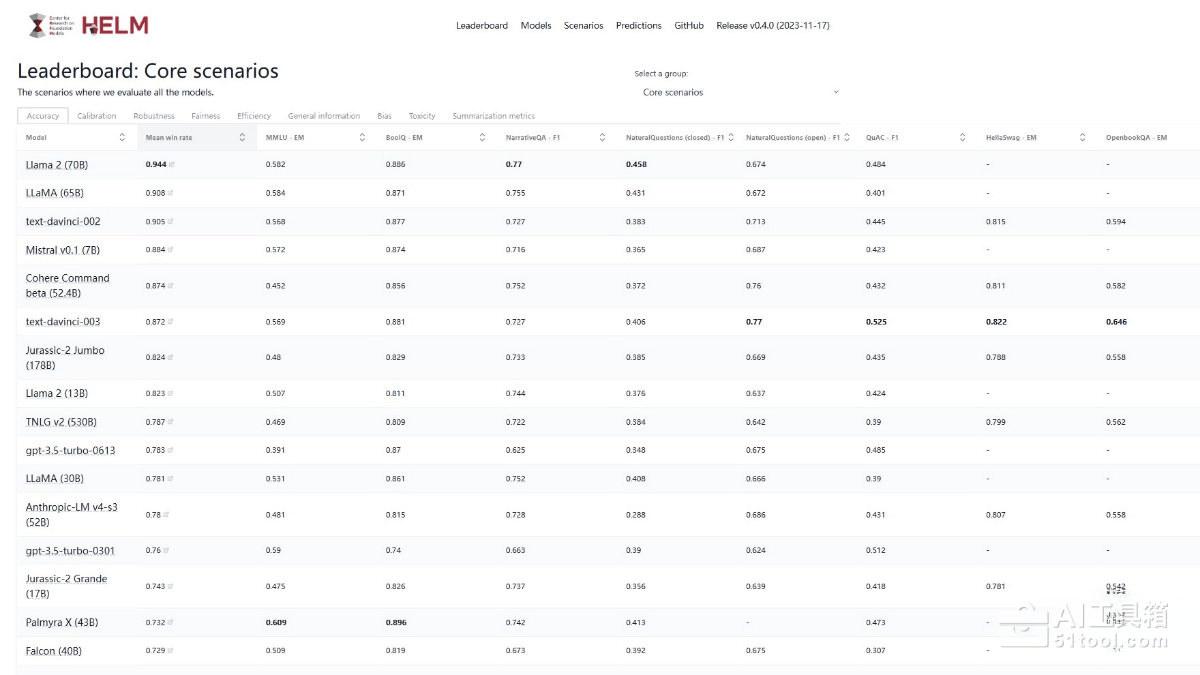
**矩阵交叉评估机制**:采用"场景×指标"的密集交叉设计,在42个应用场景中尝试测量所有7个核心指标,而非简单地将一个场景对应一个指标,从而全面揭示不同模型在能力、成本与社会风险之间的复杂权衡。
**标准化评测流程**:通过统一的提示词策略、测试集划分和公开原始数据,确保所有参评模型在相同条件下进行测试,保证评估结果的可比性和可复现性,解决传统评测方法碎片化、不透明的问题。
**自动化评测工具**:提供开源评测工具包,支持一键运行评测任务,自动生成详细的评估报告和可视化图表,大幅提升评测效率,降低人工评估成本。
**多模态模型支持**:不仅支持纯文本任务,还支持多模态任务(如图像描述生成、视觉问答等),评估多模态模型的综合性能,兼容多种AI框架和硬件架构。
### HELM的使用方法
1. **安装HELM**:通过pip安装(`pip install helm`)或从源代码安装(`git clone https://github.com/stanford-crfm/helm.git`),创建虚拟环境并安装项目依赖。
2. **配置评测任务**:创建YAML配置文件,定义要评估的任务场景、适配策略和评估指标,支持按上下文长度、输出长度、性价比、延迟等多维条件筛选模型。
3. **运行评测**:执行评测脚本(`helm run --config --model `),平台自动进行并行评测,支持使用LMDeploy或vLLM等推理框架加速评测过程。
4. **查看结果**:评测完成后,在终端或文件中查看详细的评估报告,包括各项指标的数值、对比图表等信息,分析模型在不同维度的表现。
### HELM的产品价格
HELM是完全免费的开源评测框架,用户无需支付任何费用即可使用所有评测功能、查看排行榜和下载评测报告,所有资源对研究社区开放。
### HELM的适用人群
**AI研究人员**:用于评估和比较不同语言模型的性能,推动人工智能技术的发展,为学术研究提供客观、可复现的评测基准。
**模型开发者**:在开发自动生成工具、智能助手等项目时,利用平台评测结果优化模型性能,诊断模型的优势与不足,指导模型的进一步优化。
**企业决策者**:在产品开发中应用HELM评估模型性能,为特定业务场景选择合适AI模型提供客观、透明的决策依据,优化技术选型流程。
**教育工作者和学生**:在教学中使用HELM进行AI模型的教学和研究,帮助学生理解复杂的人工智能概念,培养AI领域的专业人才。
总而言之,HELM是一款用于全面评估大模型认知能力的科学评测平台,通过42个应用场景和7个核心指标的矩阵交叉评估体系,为研究人员、开发者和企业提供公正、透明、专业的模型性能评估工具,推动大模型技术的持续发展和应用普及。
特别声明
本站51工具网提供的【HELM】工具信息资源来源于网站整理或服务商自行提交,从51工具网跳转后由【HELM】网站提供服务,与51工具网无关。如需付费请先进行免费试用,满足需求后再付费,请用户注意自行甄别服务内容及收费方式,避免上当受骗。在【收录/发布】时,该网页上的内容均属于合规合法。后期如出现内容违规或变更,请直接联系相关网站管理员处理,51工具网不承担任何责任。
51工具网专注于前沿、高效的AI工具推荐与资源整合!
本文地址https://www.51tool.com/item/951转载请注明
类似于HELM的工具