PubMedQA是什么
PubMedQA(PubMed Question Answering)是由匹兹堡大学Qiao Jin等研究人员于2019年推出的生物医学问答数据集,专门用于评估大语言模型在生物医学研究文本理解和推理方面的能力。该数据集从PubMed文献摘要中收集问题-答案对,要求模型基于摘要内容回答"是/否/可能"类研究问题,是首个需要对生物医学研究文本(尤其是定量内容)进行推理才能回答问题的问答数据集。

PubMedQA的主要功能
多维度能力评估:通过1,000个专家标注样本、61,200个未标注样本和211,300个人工生成的问答对,全面评估模型在生物医学领域的知识理解和推理能力。每个实例包含问题、上下文(摘要正文)、长答案(结论部分)和简明答案(是/否/可能),要求模型对研究结论进行判断。
推理能力测试:与简单的提取式问答不同,PubMedQA需要模型对摘要中的定量结果(如p值、置信区间、样本量对比)进行逻辑推理,才能准确判断结论的真伪,更贴近真实科研场景。
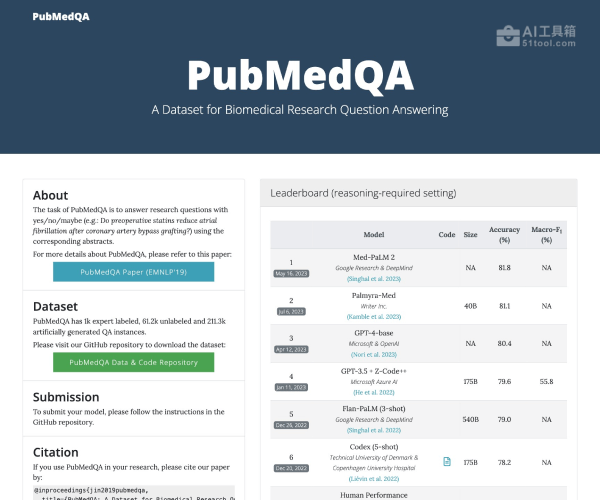
标准化评测体系:采用准确率等标准化指标提供量化性能数据,支持零样本和少样本测试模式,确保评估结果的公平性和可比性。表现最佳的模型(BioBERT多阶段微调)取得了68.1%的准确率,相比单个专家人类水平的78.0%准确率仍有提升空间。
PubMedQA的使用方法
- 获取数据集:从GitHub(https://github.com/pubmedqa/pubmedqa)或Hugging Face平台下载PubMedQA数据集,包含PQA-L(人工标注集)、PQA-U(未标注集)和PQA-A(人工生成集)三个子集。
- 数据预处理:将问题文本清洗并转换为适合模型的格式,使用提供的split_dataset.py脚本完成数据集拆分,支持对PQA-A和PQA-L数据集的拆分。
- 模型评估:准备JSON格式的预测结果(键为PMID,值为"yes"/"no"/"maybe"),通过运行evaluation.py脚本获取模型性能。若要在排行榜上提交系统,需通过电子邮件发送模型预测和系统描述给Qiao Jin。
- 人类性能评估:在拆分PQA-L数据集并生成test_set.json文件后,通过运行get_human_performance.py脚本获取人类性能基准。
PubMedQA的产品价格
PubMedQA是完全免费的开源评测数据集,用户无需支付任何费用即可使用所有评测功能、下载数据集和查看评测报告,所有资源对研究社区开放。
PubMedQA的适用人群
AI研究人员:用于评估和比较不同大语言模型在生物医学领域的性能,推动医学AI技术的发展,为学术研究提供客观、可复现的评测基准。
模型开发者:在开发医学问答系统、智能诊断助手等项目时,利用PubMedQA评测结果优化模型性能,诊断模型在生物医学推理方面的优势与不足。
医学研究人员和学生:用于医学知识问答、文献综述和学术研究,帮助快速定位相关文献中的问题解答,提升科研效率。
总而言之,PubMedQA是一款专门用于评估大语言模型在生物医学研究问答任务中表现的科学评测数据集,通过1,000个专家标注样本和创新的推理任务设计,为研究人员和开发者提供公正、透明、专业的模型性能评估工具,推动医学AI技术的持续发展和应用普及。